原文地址:https://jhalon.github.io/chrome-browser-exploitation-1/
网络浏览器是我们通往互联网的门户。如今,随着越来越多的软件应用程序以web应用程序的形式通过web浏览器交付给用户,浏览器在现代组织中扮演着至关重要的角色。你可能在互联网上做的几乎所有事情都涉及到web浏览器的使用,因此,浏览器是这个星球上使用最多的面向消费者的软件产品之一。
作为互联网的门户,浏览器也给个人计算设备的完整性带来了重大风险。我们现在几乎每天都能听到,谷歌Chrome漏洞被积极利用为零日漏洞,或谷歌确认Chrome在2022年第四个零日漏洞。事实上,浏览器漏洞并不是什么新鲜事,它们已经出现多年了,第一个已知的有文档记录的远程代码执行漏洞是CVE-1999-0280。第一个可能公开披露的浏览器漏洞是在野外使用的”Aurora“ Internet Explorer漏洞,该漏洞在12月影响了谷歌。
我对网页浏览器的兴趣第一次产生是在2018年,当时我的朋友Michael Weber向我介绍了进攻性浏览器扩展开发,这让我看到了潜在的攻击面。之后,我开始深入研究Chrome的内部结构,并开始对网络浏览器的利用非常感兴趣。因为让我们在这里诚实地说,什么样的红队不想要一个一键甚至不点击的网页浏览器漏洞。
在安全研究领域,浏览器被认为是最容易找到漏洞的目标之一。不幸的是,它们也是最复杂的研究对象之一,因为甚至开始研究浏览器内部结构都需要大量的先决条件知识,这对许多研究人员来说似乎是一个无法实现的目标。
尽管如此,我还是采取了Maxpl0it的惊人“ Introduction to Hard Target Internals”培训课程来深入学习。我强烈建议您试一试!本课程为我提供了许多背景信息,以了解Chrome和Firefox等浏览器的内部工作和内部。之后,我参加了比赛,阅读了从Chromium 博客到V8 Dev帖子的所有内容。
由于我的学习方法更像是“学习,教它,知道它”的样式,因此我发布了这个“ Chrome浏览器利用”博客文章系列,以使您对浏览器内部列表进行介绍,并在Windows上探索Chrome浏览器在Windows上的浏览器剥削。深度,我自己学习。
现在您可能会问我,为什么是chrome以及为什么Windows平台?好吧,两个原因:
- Chrome的市场份额约为73%,使其成为世界上最广泛的浏览器。
- Windows的市场份额约为90%,也是世界上使用最广泛的OS。
作为一个红队,通过学习瞄准世界上最广泛使用的软件,这使得我们发现bug、编写漏洞并成功地在战斗中使用它们的机会更大。
1 | 警告:由于浏览器、JavaScript引擎和JIT编译器的巨大复杂性,这些博客文章将是非常非常巨大的阅读量。 |
总之,在这个系列博客文章的结尾,在开始研究和利用潜在的Chrome bug前,我们将会涵盖所有我们需要了解的内容。在本系列的最后一篇文章中,我们将尝试利用CVE-2018-17463,这是Samuel Gross发现的Chrome v8优化器(TurboFan)中的JIT编译器漏洞。
那么,话不多说,让我们直接进入浏览器利用的复杂世界。
在今天的博客文章中,我们将介绍我们在深入研究之前需要充分理解的基本先决条件概念。将讨论以下主题:
- JavaScript引擎流图
- JavaScript引擎编译器工作流程
- 堆栈和寄存器机器
- JavaScript和V8内部
- 对象表示
- Hiddenclasses(地图)
- 形状(地图)过渡
- 特性
- 元素和数组
- 在内存中查看Chrome对象
- 指针标记
- 指针压缩
但是,在我们开始之前,请确保在Windows上编译v8和d8。你可以阅读我的在Windows上构建Chrome V8的要点,详细说明如何这样做。
JavaScript引擎工作流程
我们首先要了解什么是JavaScript引擎以及它们是如何工作的,以此开始我们的浏览器内部之旅。JavaScript引擎是在系统上执行JavaScript代码不可或缺的一部分。以前,它们仅仅是解释器,但现在,现代JavaScript引擎是复杂的程序,包括大量性能改进组件,如优化编译器和即时(JIT)编译。
实际上,当今实际上有很多不同的JS引擎被使用,例如:
- V8 - Google在Chrome中使用的Google开源高性能JavaScript和WebAssembly引擎。
- SpiderMonkey - Mozilla的JavaScript和WebAssembly引擎,用于Firefox。
- Charka - 由Microsoft开发的专有JScript引擎,用于IE和Edge。
- JavaScriptCore - 苹果公司内置的JavaScript引擎用于Safari中的WebKit。
那么,为什么我们需要这些JavaScript引擎以及所有复杂性呢?
众所周知,JavaScript是一种轻巧,解释型,面向对象的脚本语言。在解释型语言中,该代码是逐行运行的,并且运行代码的结果立即返回,因此我们不必在浏览器运行它之前将代码编译为不同的形式。由于性能原因,这通常不会使这种语言变得有任何好处。在这种情况下,就涉及到即时编译等编译方法地方;在这里,JavaScript代码被解析为字节码(这是机器代码的抽象),然后由JIT进一步优化,使代码更高效,在某种意义上更快。
现在,虽然上述每种JavaScript引擎都可以拥有不同的编译器和优化器,但它们几乎都是基于EcmaScript标准(也可以与JavaScript互换使用)以相同的方式设计和实现的。EcmaScript规范详细说明了浏览器应该如何实现JavaScript,以便JavaScript程序能够在所有浏览器中以完全相同的方式运行。
那么,在我们执行JavaScript代码之后,到底发生了什么呢?为了详细说明这一点,我在下面提供了一个图表,它显示了一般流程或也称为JavaScript引擎的编译管道的高级概述。
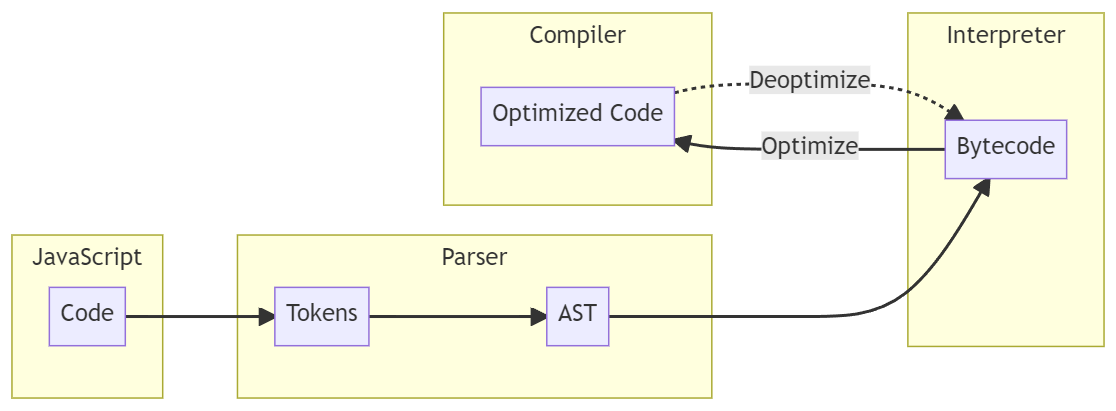
乍一看这可能会让人困惑,但别担心——这真的不难理解。因此,让我们一步一步地分解流程,并解释每个组件的作用。
解析器:一旦我们执行了JavaScript代码,代码就被传递到JavaScript引擎中,然后我们进入第一步,那就是解析代码。解析器将代码转换为以下内容:
令牌:代码首先被分解为令牌,如标识符、数字、字符串、操作符等。这被称为词法分析或标记化。
- 示例:
var num = 42被分解为var,num,=,42,然后每个令牌或项被标记为其类型,因此在本例中,它将是关键字,标识符,操作符,数字。
- 示例:
抽象语法树(AST):一旦代码被解析成令牌,解析器将把这些令牌转换成AST。这部分被称为语法分析,它做正如他所命名的,它检查以确保代码中没有语法错误。
示例:使用上面的代码示例,它的AST将如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26{
"type": "VariableDeclaration",
"start": 0,
"end": 13,
"declarations": [
{
"type": "VariableDeclarator",
"start": 4,
"end": 12,
"id": {
"type": "Identifier",
"start": 4,
"end": 7,
"name": "num"
},
"init": {
"type": "Literal",
"start": 10,
"end": 12,
"value": 42,
"raw": "42"
}
}
],
"kind": "var"
}
解释器:一旦生成了一个AST,它就被传递给解释器,解释器遍历AST并生成字节码。一旦生成了字节码,就执行它并删除AST。
可以在此处找到V8字节码的列表。
var num = 42的字节码的示例;如下所示:1
2
3
4
5
6
7
8LdaConstant [0]
Star1
Mov <closure>, r2
CallRuntime [DeclareGlobals], r1-r2
LdaSmi [42]
StaGlobal [1], [0]
LdaUndefined
Return
编译器:编译器通过使用所谓的“ Profiler”来提前工作,该工具监视和观看应优化的代码。如果有一个称为“热函数”的东西,则编译器编译该函数并生成优化的计算机代码进行执行。否则,如果它发现被优化的“热函数”不再使用了,它将反优化回到字节码。
当涉及Google的V8 JavaScript引擎时,编译管道非常相似。虽然,V8包括一个附加的“非优化”编译器,该编译器最近在2021年添加。现在V8的每个组件都有一个特定的名称,它们如下:
- Ignition: V8生成字节码的快速低级基于寄存器的解释器。
- SparkPlug: V8的新的非优化JavaScript编译器,从字节码编译,通过迭代字节码,并在访问每个字节码时发出机器代码。
- TurboFan: V8的优化编译器将字节码转换为机器代码,并具有更多的复杂代码优化。它还包括JIT(即时)汇编。

现在,如果这些概念或特性(如编译器和优化)目前没有意义,也不必担心。对于今天的文章,我们没有必要了解整个编译过程,但是我们应该对引擎作为一个整体是如何工作的有一个大致的概念。我们将在本系列的第二篇文章中更深入地讨论V8工作流程及其组件。
在那之前,如果你想了解更多关于管道的知识,我建议观看JavaScript引擎:好的部分以获得更好的理解。
JavaScript和V8内部结构
现在我们已经对JavaScript引擎及其编译器工作流程的结构有了一些基本的了解,是时候更深入地挖掘JavaScript本身的内部结构,看看V8如何在内存中存储和表示JavaScript对象,以及它们的值和属性。
如果你想要利用V8和其他JavaScript引擎中的bug,这一节是你需要理解的最重要的部分之一。因为,事实证明,所有主要的引擎都以类似的方式实现JavaScript对象模型。
正如我们所知,JavaScript是一种动态类型语言。这意味着,该类型信息与运行时值关联,而不是像c++中那样与编译时变量关联。这意味着JavaScript中的任何对象都可以在运行时轻松修改其属性。JavaScript类型系统定义了数据类型,如Undefined、Null、Boolean、String、Symbol、Number和Object(包括数组和函数)。
简单地说,这意味着什么?它通常意味着一个对象,或者像JavaScript中的var这样的原语,可以在整个运行时中改变它的数据类型,这与c++不同。例如,让我们在JavaScript中设置一个名为item的新变量,并将其设置为42。
1 | var item = 42; |
通过在item变量上使用typeof操作符,我们可以看到它返回了它的数据类型——是Number。
1 | typeof item |
现在,如果我们尝试将item设置为字符串,然后检查它的数据类型,会发生什么情况呢
1 | item = "Hello!"; |
这样,item变量现在被设置为String而不是Number的数据类型。这就是JavaScript本质上动态的原因。与c++不同的是,如果我们尝试创建一个int或integer变量,然后尝试将其设置为字符串,它将失败——就像这样:
1 | int item = 3; |
JavaScript中这一点有趣,但它确实给我们带来了一个问题。V8和Ignition(解释器)是用c++编写的,所以解释器和编译器需要清楚JavaScript打算如何使用一些数据。这对于高效的代码编译是至关重要的,特别是因为在c++中,==int==或==char==等数据类型的内存大小是不同的。
除了效率外,这对安全性也至关重要,因为如果解释器和编译器“解释” JavaScript代码错误,并且我们获得了一个字典对象而不是数组对象,那么我们现在有一个类型混淆漏洞。
那么V8是如何将所有这些信息与每个运行时值一起存储的呢?引擎又是如何保持效率的呢?
在V8中,这是通过使用称为Map的专用信息类型对象(不要与 Map Objects混淆)来完成的,该对象被称为“Hidden Class”。有时,您可能会听到Map被称为“Shape”,尤其是在Mozilla的Spidermonkey JavaScript引擎中。V8还使用在内存中使用称为==指针压缩==或==指针标记==的东西(我们将在本文中稍后讨论)来减少内存消耗,并允许V8表示内存中的任何值作为指向对象的指针。
但是,在我们深入了解所有这些函数之前,我们首先必须理解什么是JavaScript对象以及它们在V8中是如何表示的。
对象表示
在JavaScript中,对象本质上是作为键值对存储的属性集合——本质上这意味着对象的行为类似于字典。对象可以是数组、函数、布尔值、RegExp等。
JavaScript中的每个对象都有与其关联的属性,这些属性可以简单地解释为一个帮助定义对象特征的变量。例如,新创建的car对象可以具有诸如make、model和year等属性,以帮助定义car对象是什么。您可以通过简单的点符号操作符(例如objectName.propertyName)访问对象的属性或通过中括号,如objectName[‘propertyName’]。
此外,每个对象属性映射到属性的属性,这些属性用于定义和解释对象属性的状态。下面是JavaScript对象中这些属性的属性的示例。

现在,我们了解一个对象是什么,下一步是了解该对象是如何在内存中构造和存储的位置。
每当创建一个对象时,V8都会创建一个新的JSObject,并在堆上为它分配内存。对象的值是指向JSObject的指针,该JSObject在其结构中包含以下内容:
- Map: 一个指向HiddenClass对象的指针,用于详细描述对象的“shape”或结构。
- Properties: 指向包名称属性的对象的指针。
- Elements: 指向包含属性序号的对象的指针。
- In-Object Properties: 指向在对象初始化时定义的名称属性的指针。
为了帮助您可视化,下面的图像详细描述了一个基本的V8 JSObject是如何在内存中构造的。
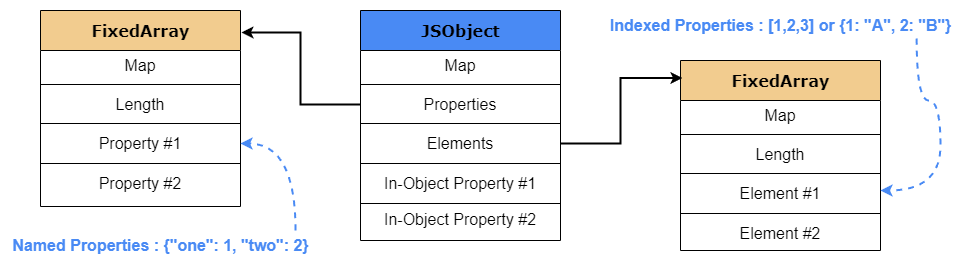
查看JSObject结构,我们可以看到属性和元素存储在两个独立的FixedArray数据结构中,这使得添加和访问属性或元素更加高效。元素结构主要存储非负整数或数组索引属性(键),通常称为元素。至于属性结构,如果对象的属性键不是一个非负整数,如字符串,属性将存储为一个内联对象属性(稍后将在文章中解释)或存储在属性结构中,有时也称为对象属性后备存储。
必须注意的一点是,虽然名称属性以与数组元素类似的方式存储,但在属性访问方面,它们是不一样的。与元素不同,我们不能简单地使用键来查找属性数组中的名称属性位置;我们需要一些额外的元数据。如前所述,V8利用了一个特殊的对象,称为HiddenClass或Map,它与每个JSObject相关联。这个Map存储了所有JavaScript对象的信息,这反过来又允许V8是动态的。
因此,在我们进一步了解JSObject结构及其属性之前,我们首先需要看看并理解这个HiddenClass是如何在V8中工作的。
HiddenClasses(Map)以及Shape 转换
如前所述,我们知道JavaScript是一种动态类型语言。特别是,由于这个原因,JavaScript中没有类的概念。在c++中,如果您创建了一个类或对象,那么您不能动态地从中添加或删除方法和属性,这与JavaScript不同。在c++和其他面向对象语言中,可以将对象属性存储在固定的内存偏移量上,因为给定类的实例的对象布局永远不会改变,但在JavaScript中,它可以在运行时动态地改变。为了解决这个问题,JavaScript使用了一种称为基于原型的继承的方法,在这种方法中,每个对象都有一个对它所包含的原型对象或shape的引用。
那么V8如何存储对象的布局?
这是HiddenClass或Map发挥作用的地方。HiddenClass与固定对象布局相似,其中属性的值(或这些属性的指针)可以存储在特定的内存结构中,然后通过 fixed-offset*在每个属性之间访问。这些偏移量由 Torque生成,可以在 V8 的 /torque-generated/src/objects/.tq.inc 目录中找到。 这几乎可以作为对象“shape”的标识符,这反过来又允许 V8 更好地优化 JavaScript 代码并缩短属性访问时间。
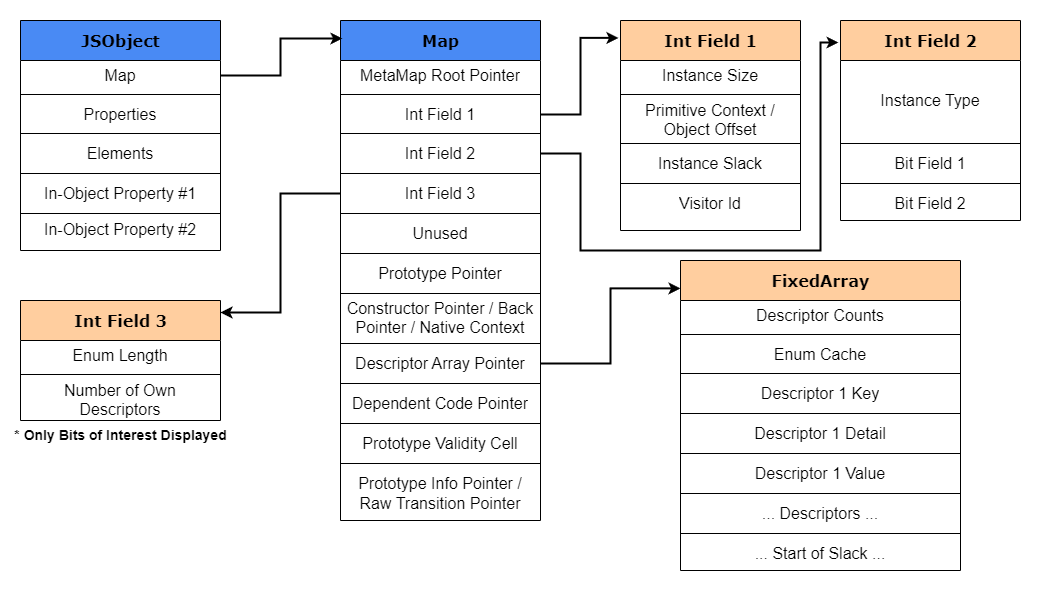
正如前面在上面的JSObject示例中看到的,Map是对象中的另一个数据结构。该Map结构包含以下信息:
- 对象的动态类型,如String、JSArray、HeapNumber等。
- V8中的对象类型列在
/src/objects/objects.h
- V8中的对象类型列在
- 对象的大小(对象内属性等)
- 对象属性及其存储的位置
- 数组元素类型
- 对象的原型或Shape(如果有)
为了帮助可视化Map对象在内存中的样子,我在下面的图中提供了一个非常详细的V8 Map结构。有关结构的更多信息可以在V8的源代码中找到,并且可以位于/src/objects/map.h 以及/src/objects/descriptor-array.h源文件中。
现在我们已经了解了Map 的布局,让我们来解释这个我们经常谈论的shape。正如您所知,每个新创建的JSObject都有自己的Hidden Class,其中包含每个属性的内存偏移量。这是有趣的部分;如果在任何时候动态地创建、删除或更改对象的属性,则将创建一个新的hidden class。这个新的隐藏类保留现有属性的信息,并包含对新属性的内存偏移量。现在请注意,只有在添加新属性时才会创建新的隐藏类,添加数组索引属性并不会创建新的隐藏类。
那么在实践中看起来如何?好吧,让我们以以下代码为例:
1 | var obj1 = {}; |
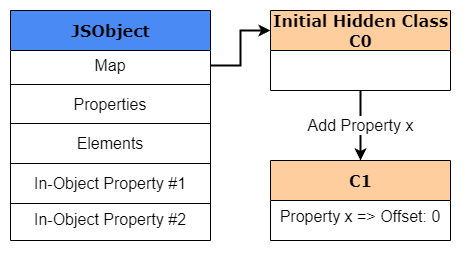
一开始我们创建一个名为obj1的新对象,它被创建并存储在V8的堆中。因为这是一个新创建的对象,所以我们需要创建一个HiddenClass(显然),尽管还没有为这个对象定义属性。这个HiddenClass也被创建并存储在V8的堆中。出于我们的示例目的,我们将这个初始HiddenClass称为C0。
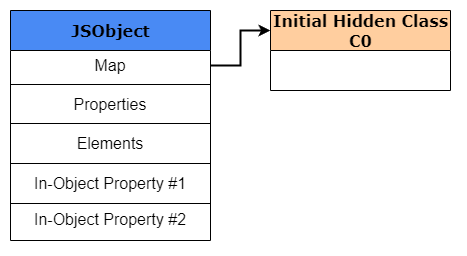
一旦到达下一行代码,当执行obj1.x = 1时,V8将基于C0创建第二个名为C1的hidden class。C1将是第一个描述属性x在内存中的位置的HiddenClass。但是,它不是存储指向x值的指针,而是存储x的偏移量,偏移量为0。
好了,可能一些人可能会问,为什么是对属性的偏移而不是对它的值?
好吧,在V8中,这是一个优化技巧。就memory 使用而言,Maps 是相对昂贵的对象。如果我们存储key,则在每个新创建的JSObject中以字典格式中的属性对,那么由于解析字典的速度很慢,这将导致大量的计算开销。其次,如果一个新的对象,如obj2被创建,它共享obj1的相同属性,如x和y,会发生什么?即使值可能不同,两个对象实际上以相同的顺序共享相同的名称属性,或者用我们的话说,相同的shape。在这种情况下,将相同的属性名存储在两个不同的位置是很浪费的。
这就是V8的速度比较快的原因,它的优化使得Map可以在相似shape的对象之间尽可能多地共享。由于相同shape的所有对象的属性名都是重复的,而且它们的顺序也是相同的,所以我们可以让多个对象在内存中指向一个单独的HiddenClass为指向属性的偏移量而不是指向值的指针。这也允许更容易的垃圾收集,因为Map和JSObject一样是HeapObject的分配。
为了更好地解释这个概念,让我们暂时从上面的示例中回顾一下,看看HiddenClass的重要部分。HiddenClass的两个最重要的部分允许Map有自己的shape,这两个部分是 DescriptorArray和第三字段。如果您回顾上面的Map结构,您会注意到第三位字段存储属性的数量,以及描述符数组,其中后者包含有关名称属性(如名称本身)的信息,该值存储的位置(offset),以及属性的属性。
例如,假设我们创建了一个新对象,例如var obj {x: 1}。x属性将存储在JavaScript对象的对象内属性或属性存储中。一旦创建了一个新对象,就会创建一个新的HiddenClass。在这个HiddenClass中,Descriptor Array和第三字段将被填充。第三字段将把NumberOfOwnDescriptors设置为1,因为我们只有一个属性。然后descriptor array将用与属性x相关的详细信息填充进数组的键、详细信息和值部分。该描述符的值将被设置为0。为什么是0 ?对象内属性和属性存储只是一个数组。因此,通过将描述符的值设置为0,V8知道对于任何相同shape的对象,键值将位于该数组的0偏移位置。
下面是我们刚才解释的一个可视化示例。

让我们看看这在V8中是什么样子的。首先,让我们使用–allow-natives-syntax参数启动d8,并执行以下JavaScript代码
1 | d8> var obj1 = {a: 1, b: 2, c: 3} |
完成之后,我们将对对象使用%DebugPrint()命令来显示它的属性、map和其他信息,例如实例描述符。执行之后,注意以下内容
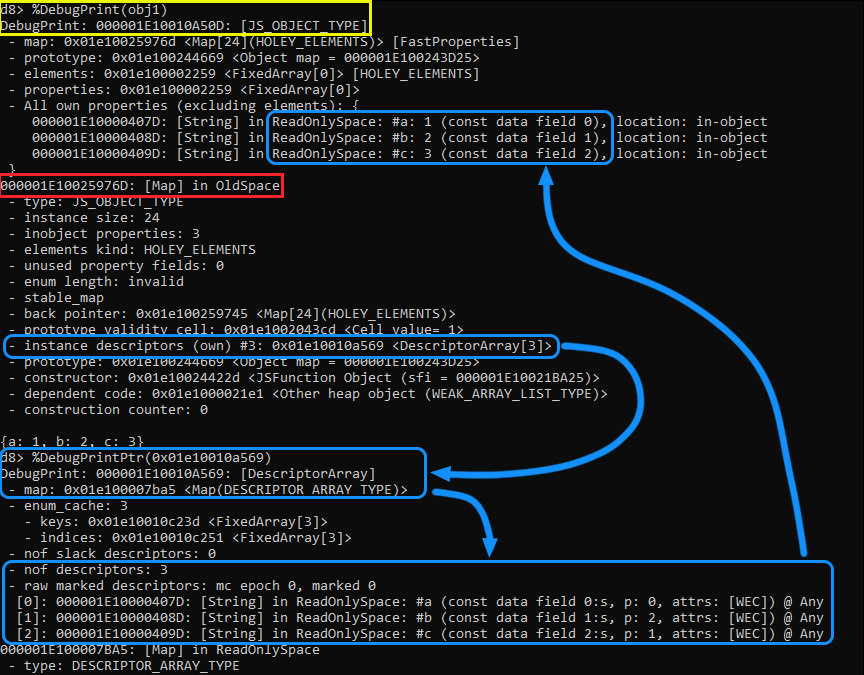
在黄色中我们可以看到我们的对象obj1。红色的是指向HiddenClass或Map的指针。在这个HiddenClass中,我们有一个指向DescriptorArray的实例描述符。使用指向该数组的指针的%DebugPrintPtr()函数,我们可以看到该数组在内存中的更多细节,用蓝色突出显示。
请注意,我们有三个属性,它们与map的实例描述符部分中的描述符数量相匹配。在下面,我们可以看到descriptor array保存着属性键,而const data字段保存着属性存储区中相关值的偏移量。现在,如果我们沿着箭头从偏移量返回到我们的对象,我们会注意到偏移量是匹配的,并且每个属性都分配了正确的值。
另外,注意在这些属性的右侧,你可以看到每个属性的位置;正如我之前提到的,它们是对象内的。这在很大程度上向我们证明了偏移量是针对In-Object和properties存储中的属性的。
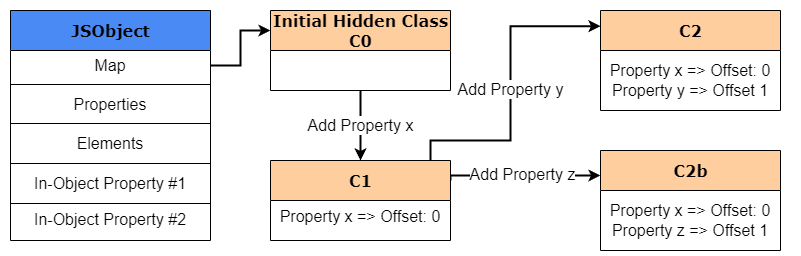
好了,现在我们理解了为什么要使用偏移量,让我们回到之前的HiddenClass示例。正如我们之前所说的,通过向obj1添加属性x,我们现在将有一个新创建的名为C1的HiddenClass,以及一个指向x的偏移量。由于我们正在创建一个新的HiddenClass, V8将用一个class transition来更新C0,该类转换声明,如果一个新对象是用属性x创建的,那么HiddenClass应该直接切换到C1。
然后在执行obj1.y = 2时重复该过程。将创建一个名为C2的新隐藏类,并将类转换添加到C1中,声明对于任何具有属性x的对象,如果添加了属性y,则隐藏类应该转换到C2。最后,所有这些类转换都会创建一个称为transition tree的东西。

另外,必须注意,class transitions取决于将属性添加到对象的顺序。因此,如果在y之前添加z,则“shape”将不再相同,并遵循从C1到C2的相同过渡路径。取而代之的是,将创建一个新的 hidden class,并将添加一个新的过渡路径,以说明该新属性,从而进一步扩展transition tree。
现在我们了解了这一点,让我们看看当一个Map在两个相同shape的对象之间共享时,对象在内存中的样子。
首先,使用–allow-native-syntax参数再次启动d8,然后输入以下两行JavaScript代码
1 | d8> var obj1 = {x: 1, y: 2}; |
完成之后,我们将再次对每个对象使用%DebugPrint()命令来显示它们的属性、映射和其他信息。执行之后,注意以下内容
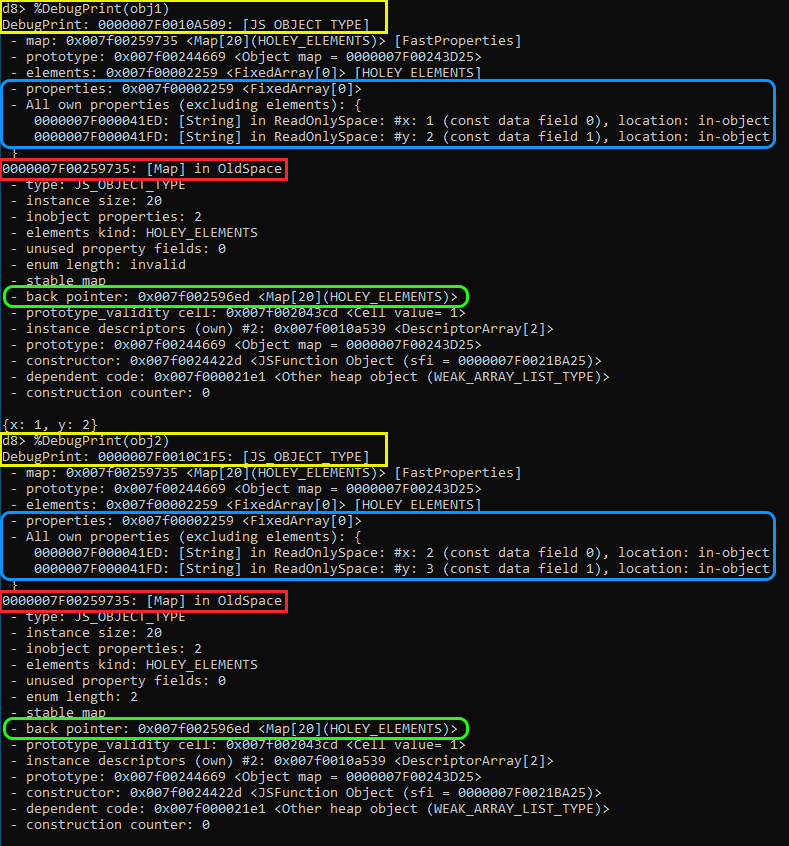
在黄色中我们可以看到我们的两个对象,obj1和obj2。请注意,每个对象都是JS_OBJECT_TYPE,在堆中有不同的内存地址,因为显然它们是具有潜在不同属性的独立对象。
正如我们所知,这两个对象共享相同的shape,因为它们都以相同的顺序包含x和y。在这种情况下,在蓝色中,我们可以看到属性在相同的FixedArray中,x和y的偏移量分别为0和1。这是因为我们已经知道,相同shape的对象共享一个HiddenClass(用红色表示),它将具有相同的descriptor array。
正如您所看到的,对象的大多数属性和Map地址将是相同的,这都是因为这两个对象共享同一个Map。
现在让我们关注用绿色突出显示的back_pointer。如果您回顾一下我们的C0到C2映射转换示例,您会注意到我们提到了一个称为transition tree的东西。这个transition tree是在V8每次创建一个新的HiddenClass时在后台创建的,它允许V8将新的和旧的HiddenClass链接在一起。这个back_pointer是transition tree的一部分,因为它指向发生转换的父map。这允许V8遍历向后指针链,直到找到持有对象属性的map,即对象的shape。
让我们使用d8来深入了解它是如何工作的。我们将再次使用%DebugPrintPtr()命令来打印V8中的地址指针的详细信息。在本例中,我们将采用Back_pointer地址来查看其详细信息。一旦完成,您的输出应该与我的类似。
在绿色中,我们可以看到Back_pointer在内存中指向了JS_OBJECT_TYPE类型,这实际上是一个Map!该Map是我们之前提到的的C1。我们知道Map如何回溯到其先前的Map,但它是如何知道当添加属性时要转换到哪一个Map?好吧,如果我们密切关注该Map中的信息,我们会注意到在instance descriptor 指针下方,有一个红色“transitions”部分。该transitions部分包含Map结构中的原始Transition 指针指向的信息。
在V8中,Map转换使用一个叫做 TransitionsAccessor的东西。这是一个辅助类,它封装了Map可以转换到到其各自字段中其他Map的访问方式。在Map::kTransitionsOrPrototypeInfo(为我们前面提到的原始转换指针)上存储。这个指针指向一个叫做TransitionArray的东西,它也是一个FixedArray,用于保存为了准备属性更改的map转换。
回顾红色突出显示的部分,我们可以看到该TransitionArray中只有一个转换。在该数组中,我们可以看到该转换#1详细介绍了将Y属性添加到对象时的转换。如果添加Y,它告诉Map将其更新为与我们当前Map匹配的0x007F00259735中存储的Map!如果有另一个转换,例如,z被添加到x而不是y中,那么我们将在该转换数组中有两个条目,每个条目都指向其相应的对象shape的map。
1 | 注意:如果你想仔细了解和转换的另一种可视化表示,我建议使用V8的[Indicium]工具。该工具是一个统一的web界面,允许用户跟踪、调试和分析如何在现实应用程序中创建和修改的模式。 |
现在,如果我们删除一个属性,转换树会发生什么?在这种情况下,V8在每次属性删除时创建一个新的Map是有细微差别的。正如我们所知,当涉及到内存使用时,Map是相对昂贵的,因此在一定程度上继承和维护transition tree的成本将变得更大和更慢。在对象的最后一个属性被删除的情况下,Map只会调整back_pointer以返回到它的前一个Map,而不是创建一个新的Map。但是如果我们删除一个对象的中间属性会发生什么呢?在这种情况下,每当我们添加太多属性或删除非last元素时,V8都会放弃维护过渡树,并且它将切换到称为字典模式的较慢模式。
那么,这个字典模式是什么?好吧,既然我们知道V8如何使用HiddenClass来跟踪对象的形状,那么我们现在可以回到完整的circle ,进一步深入了解这些属性和元素实际上如何在V8中存储和处理。
属性
如前所述,我们知道JavaScript对象具有两种基本属性:名称属性和索引元素。我们将首先讲讲名称属性。
如果您回想起了我们在Map和Descriptor Array的讨论,我们提到了名称属性,该属性被存储为“对象内”或“属性数组”中。我们正在谈论的这项In-Object属性是什么?
好吧,在V8中,此模式是将属性直接存储在对象上的非常快的方法,因为它们可以无需任何间接访问。尽管它们非常快,但也受限于对象的初始大小。如果添加更多的属性,则与对象中的空间相比,新属性存储在属性存储中 ,间接增加了一层。
通常,JavaScript引擎使用两个“模式”来存储属性,这些被称为:
- 快速属性:通常用于定义在线性属性存储中存储的属性。通过查询HiddenClass中的Descriptor Array数组,可以通过属性存储中的索引简单地访问这些属性。
- 慢速属性:也称为“字典模式”,当添加或删除太多属性时,将使用此模式 ,将导致大量内存开销。结果,具有慢速属性的对象将具有独立的字典作为属性存储。所有属性元信息不再存储在Hiddenclass的Descriptor Array中,而是直接存储在属性字典中。然后,V8将使用哈希表访问这些属性。
在下面可以看到Map转换到使用独立字典缓慢属性的示例。

这里还必须注意一件事。shape转换只适用于快速属性而不适用于缓慢属性,因为字典Shape仅由单个对象使用,因此它们不能在不同对象之间共享,因此没有转换。
元素
好了,到这里我们已经基本讲到了命名属性。现在让我们看看数组索引的属性或元素。有人会认为索引属性的处理会不那么复杂,但这样假设是错误的。元素的处理并不比命名属性简单。尽管所有的索引属性都保存在元素存储区中,V8对每个数组包含的元素类型进行了非常精确的区分。实际上有大约21种不同类型的元素可以在这个存储中被跟踪!这最初允许V8针对特定类型的元素优化数组上的任何操作。这是什么意思呢?好吧,让我们以这行代码为例
1 | const array = [1,2,3]; |
在JavaScript中,如果我们对它运行typeof操作,它会说数组包含数字,因为JavaScript不区分整数、浮点数或双精度数之间的区别。然而,V8做了更精确的区分,并将这个数组分类为一个PACKED_SMI_ELEMENTS,其中SMI指的是小整数。
那么,SMI是怎么回事呢?V8会跟踪每个数组包含的元素类型。然后,它使用该信息优化这种类型元素的数组操作。在V8中,我们需要了解三种不同的元素类型,它们是
SMI_ELEMENTS- 用于表示包含小整数的数组,例如1,2,3,等等。DOUBLE_ELEMENTS- 用于表示包含浮点数的数组,例如4.5、5.5,等。ELEMENTS- 用来表示包含字符串字符字面元素或值的数组,该数字或值不能表示为SMI或double,例如“ x”。
那么V8如何将这些元素类型用于数组?它们是为数组还是为每个元素设置?答案是为数组设置了元素类型。我们必须记住的重要一件事是,元素类型的“转换”只能朝一个方向发展。我们可以从“自上向下”方法查看这种转换树。
例如,让我们以前面的数组为例:
1 | const array = [1,2,3]; |
正如您所看到的,V8将这个数组的元素类型作为一个打包的SMI来跟踪(我们稍后将详细介绍什么是打包的)。现在,如果我们要添加一个浮点数,那么数组的元素类型将转换为Double元素类型。
1 | const array = [1,2,3]; |
这种转变的原因很简单,就是操作优化。因为我们有一个浮点整数,V8需要能够对这些值进行优化,以便向下一步过渡到double,因为可以表示为SMI的一组数字是可以表示为double的数字的子集。.
由于元素类型的转换是单向的,因此,一旦数组被标记为较低的元素类型,例如PACKED DOUBLES elements,即使我们替换或删除了浮点整数,它也不能再返回到wrapped SMI elements。通常,在创建数组时,元素类型越特定,启用的优化就越细粒度。元素越往下走,对对象的操作就可能越慢。
接下来,我们还需要理解V8在索引被删除或为空时跟踪元素备份存储时的第一个主要区别。这是
PACKED- 用于表示密集的数组,这意味着数组中的所有可用元素均已填充。HOLEY- 用于表示其中具有“孔”的数组,例如删除索引元素或未定义的索引元素时。这也被称为制作阵列“稀疏”。
让我们仔细看看这个。例如,让我们以以下两个数组为例
1 | const packed_array = [1,2,3,5.5,'x']; |
正如您所看到的,holey数组中有洞,因为我们忘记将3添加到索引中,只是将其留空或未定义。V8之所以做出这样的区分,是因为在packed 数组上的操作可以比在Holey数组上的操作更积极地优化。如果你想了解更多,那么我建议你观看Mathias Bynens的面向JavaScript开发者的V8内核的演讲,其中详细说明了这一点。
V8还在wrapped和HOLEY数组上实现了前面提到的元素类型转换,这形成了一个格栅。下面是V8博客中这些转换的简单可视化。

同样,我们必须记住元素类型在格中有单向向下的转换。例如,向SMI数组添加一个浮点数将把它标记为double,同样,一旦数组中创建了一个空洞,它将永远标记为holey,即使您稍后将其填充。
V8还对我们需要理解的元素进行了第二个主要区分。在元素后备存储区中,就像在属性存储区中一样,元素也可以是快速模式或字典模式(慢模式)。快速元素只是一个数组,其中属性索引映射到元素存储中项目的偏移量。对于慢数组,这种情况发生在只有少量条目的大型稀疏数组中。在这种情况下,数组后备存储使用字典表示,例如我们在属性存储中看到的,以牺牲性能为代价来节省内存。该字典将在字典三元组值中存储键、值和元素属性。
查看内存中的Chrome对象
在这一点上,我们涵盖了许多关于JavaScript和V8内部的复杂主题。希望在这一点上,你已经对V8在底层工作的一些概念有了一定的理解。现在我们有了这些知识,是时候开始观察V8和它的对象通过WinDBG观察时在内存中的样子了,以及使用了什么类型的优化。
我们使用WinDBG的原因是,当我们将编写利用程序,调试我们的POC等,我们将主要使用WinDBG结合d8。在这种情况下,我们能够掌握和理解V8内存结构的细微差别是有益的。如果您不熟悉WinDBG,那么我建议您阅读并熟悉Microsoft的入门WinDBG(用户模式)博客文章,如果您以前使用过GDB,则阅读针对WinDBG用户的GDB命令。
我知道我们已经研究了对象和映射的内存结构,并在d8上做了一些混乱的处理——所以我们应该对什么指向什么以及东西在内存中的位置有一个大致的概念。但是,不要以为这很容易。与V8中的所有东西一样,优化在使它快速和高效方面发挥了重要作用,这也适用于它如何处理和在内存中存储值。
这是什么意思呢?让我们快速浏览一下使用d8和WinDBG的简单V8对象结构。首先,让我们使用——allow-native -syntax选项再次启动d8,并创建一个简单的对象,例如
1 | d8> var obj = {x:1, y:2} |
完成之后,让我们继续使用%DebugPrint()函数来打印对象信息。
1 | d8> var obj = {x:1, y:2}; |
然后,启动WinDBG并将其附加到d8进程。一旦连接上调试器,我们将执行dq命令,后面跟着对象的内存地址(0x0000020C0010A509),以显示其内存内容。你的输出应该和我的差不多。
研究WindBG输出,我们可以看到我们正在使用对象的正确内存地址。但是,当我们查看内存内容时,第一个地址(应该是指向地图的指针 - 如果您回想起我们的JSOBJECT结构)似乎已被损坏。好吧,人们会认为它已经破坏,经验丰富的反向工程师或利用开发人员甚至会认为存在偏移/对齐问题,从技术上讲,您会很接近,但不正确。
这又是我的朋友V8的优化在工作。您可以看到为什么我们需要讨论这些优化,因为对于未经训练的人来说,您会对内存中正在发生的事情感到非常困惑。我们实际上在这里看到的是两件事——指针压缩和指针标记。
我们将首先理解V8中的指针或值标记。
指针标记
什么是指针标记,为什么要使用它?正如我们所知,在V8中,值被表示为对象并分配到堆上——无论它们是对象、数组、数字还是字符串。现在,许多JavaScript程序实际上对整数值执行计算,所以如果我们每次增加或修改一个值时都必须在JavaScript中不断地创建一个新的Number()对象,那么这将导致创建对象的时间开销、堆跟踪,并增加所使用的内存空间,使其非常低效。
在这种情况下,V8会做的是,不是每次都创建一个新对象,它实际上会内联存储一些值。虽然这是可行的,但它给我们带来了第二个问题。问题是,我们如何区分对象指针和内联值?这就是指针标记发挥作用的地方。
指针标记技术的基础是观察到在x32和x64系统上,分配的数据必须在字对齐(4字节)的边界上。因为数据是以这种方式对齐的,所以最低有效位(LSB)总是为零。然后,标记将使用底部的两个位或最低有效位来区分堆对象指针和整数或SMI。
在x64体系结构上,使用以下标记方案
1 | |----- 32 bits -----|----- 32 bits -------| |
从示例中可以看出,0用于表示SMI, 1用于表示指针。需要注意的一点是,您正在查看内存中的SMI,虽然它们是内联存储的,但它们实际上是加倍的,以避免指针标记。所以,如果初始值是1,那么内存中的值就是2。
在指针内部,第二个LSB中还有一个w,它表示一个用于区分强指针引用或弱指针引用的位。如果您不熟悉什么是强指针和弱指针,我将解释。简单地说,强指针是指指向的对象必须保留在内存中(它代表一个对象)的指针,而弱指针是指指向可能已经删除的数据的指针。当GC或垃圾收集器删除一个对象时,它必须删除强指针,因为它是保存引用计数的指针。
使用这种指针标记方案,对整数的算术或二进制操作可以忽略标记,因为低32位将全为0。然而,当涉及到对HeapObject的解引用时,V8需要先屏蔽掉LSB,将使用一个特殊的访问器用来清理LSB。
现在,让我们回到WinDBG中的示例,通过从地址中减去1来清除LSB。这将为我们提供有效的内存地址。一旦完成,您的输出应该如下所示。

正如您所看到的,一旦我们清除LSB,我们现在在内存中有了有效的指针地址!我们有map ,属性,elements,还有内联对象。同样,请注意SMI是两倍的,所以包含1的x在内存中实际上是2,同样适用于2,因为它现在是4。
对于那些目光敏锐的人来说,您可能已经注意到,实际上只有一半的指针指向内存中的对象。这是为什么呢?如果你的答案是另一种优化,那么你是对的。这叫做指针压缩,我们现在会讲到。
指针压缩
Chrome和V8中的指针压缩利用了堆上对象的有趣属性,这就是堆对象通常彼此接近,因此指针中最重要的位数可能是相同的。在这种情况下,V8仅将指针的一半(包含LSB位)保存到内存中,并将V8堆(称为孤立根)的最显着的位(上部32位)放入根寄存器(R13)中。每当我们需要访问指针时,寄存器和内存中的值都会添加在一起,我们将获得完整的地址。压缩方案是在V8中的/src/common/ptr-compr-inl.h源文件中实现的。
基本上,V8团队试图实现的目标是某种程度上将两种标记值拟合到64位体系结构中,特别是为了减少V8中的开销,以尝试使尽可能多的浪费4个字节在可能的内部。X64体系结构。
尾声
这就是我们深入了解JavaScript和V8内部的全部内容!我希望你喜欢这篇文章,我真诚地希望它能帮助你了解V8的复杂性。
我知道要介绍的内容很多,而且老实说,一开始它非常复杂——所以请花时间通读本文,并确保您理解了基本概念,因为在我们使用它之前,您需要理解所有这些在底层是如何工作的。记住,要知道如何打破一个东西,我们首先要知道它是如何工作的。
在本系列博客文章的第二部分中,我们将进一步了解编译器工作流程,并解释在Ignition、Spark-Plug和TurboFan中发生了什么。我们还将更多地关注JIT编译器、推测性守卫、优化、假设等,这将使我们更好地理解常见的JavaScript引擎漏洞,如类型混淆。
参考链接
- Attacking JavaScript Engines - A Case Study of JavaScriptCore and CVE-2016-4622
- A Tale of Types, Classes, and Maps by Benedikt Meurer
- A tour of V8: Object Representation
- Exploiting Logic Bugs in JavaScript JIT Engines
- Fast properties in V8
- How is Data Stored in V8 JS Engine Memory
- JavaScript Engine fundamentals: Shapes and Inline Caches
- JavaScript Engines Hidden Classes
- Javascript Hidden Classes and Inline Caching in V8
- Juicing V8: A Primary Account for the Memory Forensics of the V8 JavaScript Engine
- Learning V8
- Mathias Bynens - V8 Internals for JavaScript Developers
- Pointer Compression in V8
- SMIs and Doubles
- V8 / Chrome Architecture Reading List - For Vulnerability Researchers
- V8 Dev Blog
- V8 Engine JSObject Structure Analysis and Memory Optimization Ideas
- V8 Hidden Class